Die neue Google Search Console (beta) bietet Admins einen Ausblick auf das zukünftige Dashboard zur Google's Crawler-Aktivität. Zeit, das Board mal unter die Lupe zu nehmen...
Viele Webmaster und SEO-Professionals kennen die Google Search Console zur Analyse der Crawler-Konformität der eigenen Homepage sicherlich bereits: https://www.google.com/webmasters/tools/search-analytics
Mit Hilfe diesen Tools sieht ein geschultes Webmaster-Auge...
- wo es auf der Homepage knackt und knarzt,
- wo es Fehler gibt,
- wo Google's Crawler Probleme mit der Indizierung hat und vor allem
- wo die Website nicht Google's Vorstellung vom idealen Web entspricht.
Das alles hat Auswirkungen auf das Ranking bei der Google Suche. Eine ordentliche Pflege an dieser Stelle ist, wie ich es nun erleben durfte, das A und O für ein Top-Ranking.
Neuerdings bietet Google auch ein neues, hippes Dashboard (beta) an, das ein paar wichtige Details über den Gesundheitszustand der eigenen Website verrät.
Jedes für sich ist schon ein gutes Werkzeug, aber zusammen sind die Boards bares Gold wert.
Ich bin zwar kein Experte in dem Bereich, aber einige Fehler im SEO Bereich fallen einem mit den richtigen Tools wie Schuppen vor die Augen und sorgen fast von allein für den nötigen Aha-Effekt.
Wer grundsätzliches Interesse an der Google SEO hat, sollte auf jeden Fall die Support-Seiten studieren. Im Besonderen geht's unter Unseren Richtlinien folgen sehr interessant zu.
Es verbergen sich also viele elementare Tipps hinter diesen unzähligen Webseiten. Darunter einige sehr wichtige, die ich allen ans Herz legen will, die dem Thema immernoch wenig Beachtung schenken.
Status Quo
Auf meiner Website hat es in der Vergangenheit nette Crawling-Aktivität gegeben, die mich zwar nicht vom Hocker gerissen hat, aber die mir auch nicht sonderlich seltsam vorkam. Ich nahm hin was der Crawler da getrieben hat und war glücklich.
Bis irgendwann Ende August die, ohnehin spärlichen Klickraten fast auf Null abgesackt sind. Ich wurde leicht unruhig, aber wußte mir nicht zu helfen - außerdem Stand das Release von Argh! Earthlings! vor der Tür und ich wollte mich nicht um alles gleichzeitig kümmern.
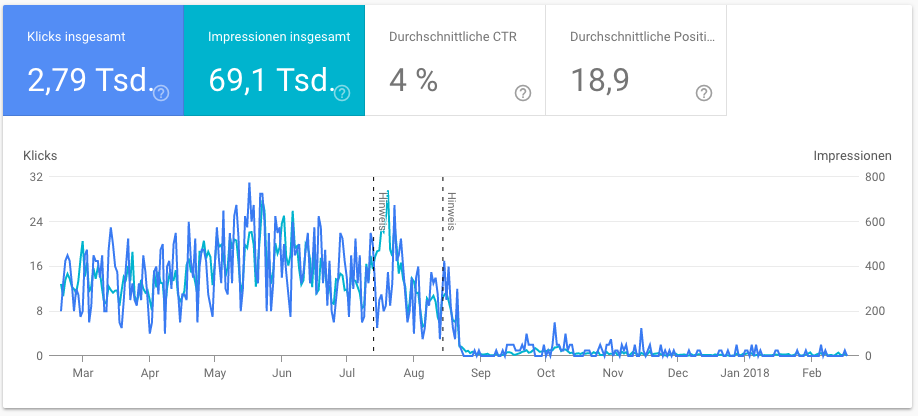
Man bemerke die beiden Hinweise von Google zu anstehenden, bedeutenden Änderungen im Crawler-Verhalten. Der zweite fühlt sich wie ein Strafzettel für's Falschparken an. Au!
Inzwischen habe ich aber endlich Zeit gefunden... und auch die Gründe der schlechten Wahrnehmung im Google Index:
404 und ähnliche "Anomalien"
Zuallererst ging's darum den Website zu entlausen. Fehlerhafte Links und nicht auffindbare Seiten mussten auf unterschiedliche Weise behandelt werden.
- Auf meiner Seite gab es zuvor ein kleines HTML-Code Snippet, das von JavaScript als Template verwendet wurde. Dieses produzierte aber für Anchors mit href-Attribut und einem Platzhalter einen verlockenden Link für den Bot. Wurde dieser also verfolgt, landete der Bot im Nirvana: HTTPS Code 404. Kein Zustand mit dem man um einen bessern Rank werben sollte.
- Darüberhinaus gab es natürlich auch echte verunglückte Links. Die Seite ist mit den Jahren gewachsen und wies hier und da einen gewissen, unbemerkten Verfall auf. Das Board ist aber schonungslos gründlich. Jede angemeldete Seite, die nicht gefunden wurde, wird angeprangert. Nachdem die defekten Links gegen neue ausgetauscht wurden, war Ruhe im Karton.
- Einige Fälle von Fehlleitung lassen sich lokal nicht sauber korrigieren. Hier muss man einwenig in die Trickkiste greifen. So verweist ein externer Link auf eine Seite, die es nicht gibt. Diese ist mir aber so wichtig, dass ich sie angelegt habe, um den Aufrufer an die richtige Stelle zu leiten. Dem Google Crawler gefällt's.
Als nächstes folgen Optimierungen, die die Website mit ihrer Dynamik nicht leisten kann.
Sitemap für die Orientierung
Die Website ist statisch. Alle Inhalte sind mit Jekyll vorbereitet und per Markdown gepflegt, siehe Blog-Artikel: jekyll Kickstart. Dadurch fehlt aber ein Stück Dynamik das mir das Leben bei der Pflege erleichtert. Dieses kompensiere ich mit JavaScript. So ist etwa die Blog-Übersicht im Browser zusammengesetzt, und damit unverständlich für Crawler. Damit der Crawler aber die Website durchleuchten kann, gibt es zum Glück die Meta-Ebene: die Sitemap.
Es ist u.a. eine standardisierte XML Datei mit allen Links, denen der Crawler folgen soll. Also auch denen, die man sich dynamisch zusammensetzt. Ideal für meine Website.
Den Anweisung von Google Folge geleistet, habe ich nun die Einstiegs-Sitemap erstellt und dazu noch eine Blog-Seitemap hinzugepackt. Diese wird per Jekyll bei jeder Änderung zusammengebaut, und mein Job besteht am Ende lediglich darin diese eine Datei mit dem Server zu synchronisieren. Fertig. Google muss nur noch angewiesen werden die neue Datei zu scannen und zwei Tage darauf sind alle Artikel durchsuchbar.
Mit Kanonen auf Dupletten geschossen
Leider schließt Google einen ganzen Haufen der Artikel aus seinem Index aus und meldet es wären zu viele "Nicht-Kanonische" Duplikate entdeckt worden. Ich habe mit diesem Begriff bisweilen wenig anfangen können. Wieso sollte jemand meine Website 1:1 klonen? Großes Unverständnis.
Das Problem war aber so schnell gelöst, wie es aufgetaucht war. Offenbar braucht Google eine absolute Web-Adresse im Head-Teil jeder Seite, um die Echtheit der Inhalte prüfen zu können.
<link rel="canonical" href="httqs://www.meinewebseite.net/pfad/zum/original/dokument.html" />
Da ich nun mit einem passenen Layout unter Jekyll alle Blog-Artikel auf einen Streich anpassen konnte, war das Thema im Nu vom Tisch. Alle Artikel zeigen nun auf die eine Original-Quelle und fertig aus.
Details unter Doppelte URLs zusammenfassen / Kanonische Seite für ähnliche oder doppelte Seiten festlegen
Erreichbarkeit mit und ohne www
Als Nächstes kümmerte ich mich um die Erreichbarkeit der Domain. Da mein Hoster bisher die Domain mit und ohne www angeboten hatte, sollte ich mich für eine entscheiden.
Googles Console bietet hierzu ein passendes Web Tool an, nachdem man alle seine "Propertys" angemeldet hat. Das war mir aber zu wenig. Warum sollte ich beide anbieten müssen, wenn es doch nur eine offizielle gibt und Google mit der Nase drauf gestoßen werden muss? Zumal Google weiterhin beide Domains durchsuchen wird und nicht Ruhe gibt, so die Doku.
Also ist das Einfachste und Sicherste eine Regel in die .htaccess-Datei einzuhängen, die eine stupide aber wirkungsvolle 301-Weiterleitung durchführt. Siehe Seiten-URLs mit 301-Weiterleitungen ändern.
Aber falls der Hoster dies auch anderes anbietet, sollte man dem Rat des Hosters folgen. Unsachgemäße Änderungen an den Konfigurationen können im Chaos enden. ...Und ich wette, diese Dateien sind dann nicht einmal in einem Versionkontrollsystem, wie Git, gespeichert... na, hab ich recht?
HTTP vs. HTTPS
Das, was aber definitiv zur sichtbaren Leistungssteigerung bei Google führte, war in meinem Fall der Wechsel der Links von HTTP zu HTTPS. Mein Hoster hat mir ein gültiges Zertifikat ausgestellt, und das kann ich prima Goolge under die Crawler-Nase halten.
Vor der Umstellung war die Menge der Impressionen der letzten 28 Tage recht mau.
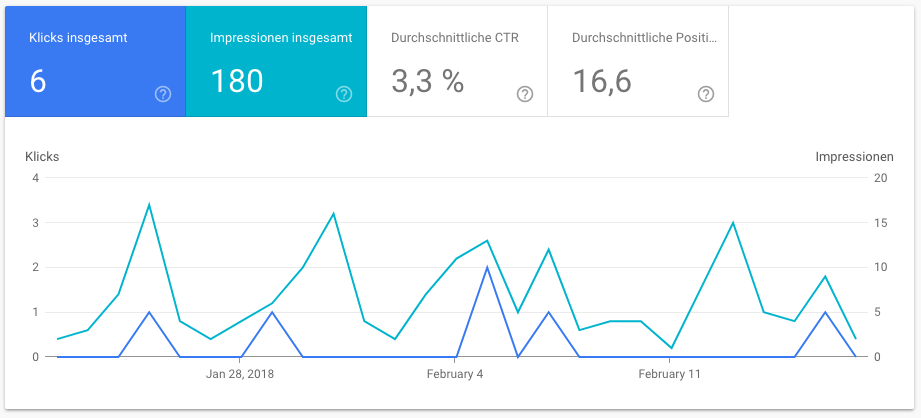
Aber nach dem Wechsel zu HTTPS war innerhalb von nur 3 Tagen endlich Bewegung zu sehen. Diese letzte Maßnahme hat der Website die nötigen Brusthaare verpasst.
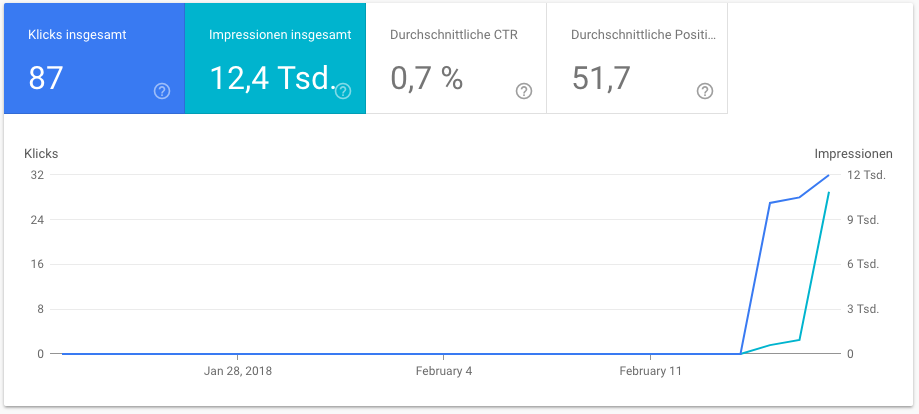
Die Impressionen haben innerhalb von nur 3 Tagen 1/6 der Jahressumme von 2017 erreicht. Das kann sich sehen lassen. Ich bin mal auf die Zahlen in 28 Tagen gespannt.
Lessons Learned
Die Crawler sind schon recht anspruchsvoll und verlangen dem Webmaster und/oder SEO einiges an Tuning ab. Die alte, sowie die neue "Search Console" gehören nun ab sofort höchstoffiziell in meinen digitalen Werkzeugkasten.